Table of Contents
Project Overview
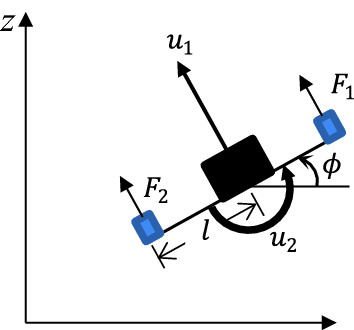
In this project, I created a deep deterministic policy gradient (DDPG) reinforcement learning agent in Tensorflow to learn the dynamics of a two-dimensional drone. This project is an example of model-free RL since the agent has no knowledge of the drone’s kinematics or dynamics. I created my own OpenAI Gym environment where I implemented the drone’s dynamics in the step function. The 2D drone is controlled by two control inputs – total thrust produced by both rotors and roll angle acceleration.
Terminal Conditions
I am trying to get the agent to navigate the vehicle to the reference point with coordinates (x,y). I impose a number of terminal conditions to end each episode during training to speed up the process and impose
limits on the agent. The episode is ended if any of the following conditions are met:
- the x and y states are within their target values by margin epsilon. This ends the episode if the quadrotor reaches its goal state.
- the total distance between the agent
and the target setpoint exceeds 100 meters. This ends the episode in the event that the agent flies off too far. - the height of the agent is less than or equal to zero. This prevents the quadrotor from flying below the “floor”.
- the x or y velocity of the agent exceeds 10 m/s. This prevents wild and unrealistic flight paths.
- the roll angle exceeds 1 radian or 58 degrees. I noticed that the quadrotor would reach the goal but by spinning unrealistically about its center of mass. This constraint eliminated the spinning issue.
Once the terminal states are set, I setup the reset function that brings the environment back to it’s starting configuration for each episode. Then I implement the calc_reward function which calculates and returns the reward for every step.
Reward Function
In order to incentivize the agent to follow the path I set, I reward the agent as it approaches the target setpoint. I offer exponentially more reward the closer the agent is to my target. I found that sparse rewards did not really work well for this framework and took much longer to converge. The reward function is given below:
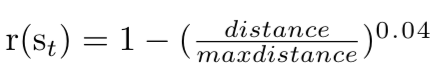
DDPG RL Agent
The DDPG agent is deterministic. In order to encourage the agent to explore vs exploit, a gaussian white noise is added to the action space during training. The DDPG framework also makes use of a replay buffer as well as target networks. The replay buffer holds the last 100,000 sequences of states, rewards, next states and terminal flags. The agent samples from this as it chooses new actions. DDPG is an actor critic method. For the actor network, the update process consists of randomly sampling states from the replay buffer, using the actor to determine the corresponding actions for those states, plugging those actions into the critic to get a value, and then taking the gradient with respect to the actor’s parameters. For the critic’s update process, it randomly samples states, new states, actions and rewards from the replay buffer, uses the target network actor to determine the actions for those states, plugs those actions into the target critic to get a value, and then plugs those values into the real critic to get its value. The difference between the values generated by the critic and the target critic is compared with mean squared error (MSE) and is used to update the weights of the critic.
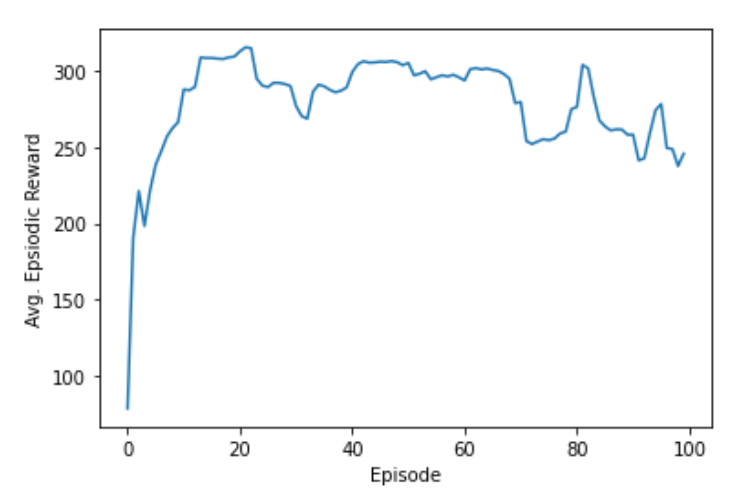
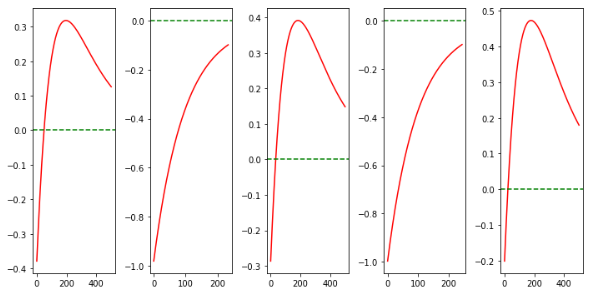
Training
Random Policy - Results
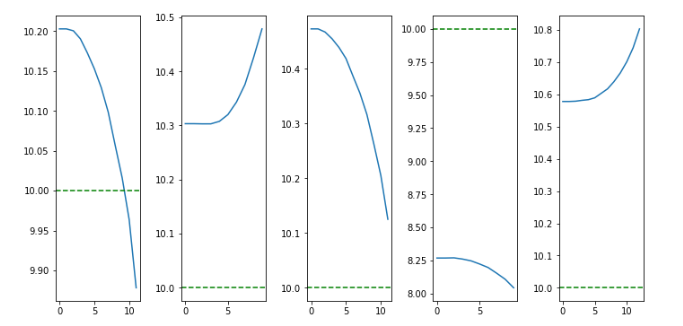
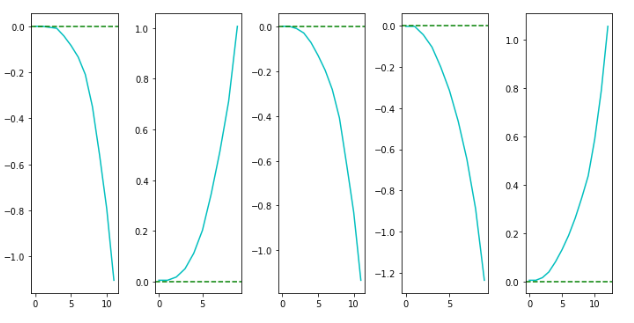
Learned Policy - Results
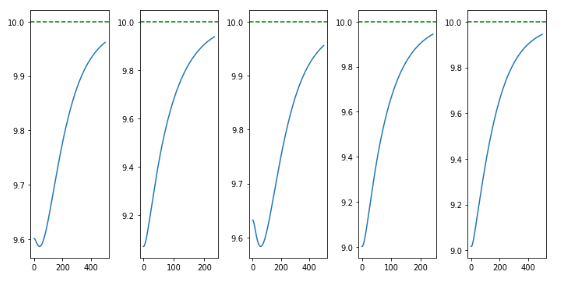
Code
"""2D_Quad_Env.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/11uUsoOVA-nWca9vowDETArHCRDwxRm_M
"""
from gym import Env
import numpy as np
from gym.spaces import Box
import math
import tensorflow as tf
from tensorflow.keras.layers import Dense, Input, Concatenate, Lambda
import matplotlib.pyplot as plt
class Quad2DEnv(Env):
def __init__(self):
self.target_z = 10
self.target_y = 0
self.target_phi = 0
# define constants
self.Ts = 0.01
self.episode_step = 500
self.g = 9.8
self.m = 20
self.Ixx = 4.856e-3
self.eps = 0.1
self.flyOffThreshold = 100
self.crashHeightThreshold = 0
self.action_space = Box(low = np.array([500,-1000, 1550.7, -1000, -1000, 209.9, -1, -1, 0.1065, -1, -1, 0.0424]),
high = np.array([1500,-1, 1550.7, -1, -1, 209.9, -1e-7, -1e-7 , 0.1065, -1e-7, -1e-7, 0.0424]), dtype=np.float32)
self.observation_space = Box(low = np.array([-100,-100,-1,-100,-100,-1,-100,-100, -100]), high = np.array([100,100,1,100,100,1, 100, 100, 100]), dtype=np.float32)
self.state = np.array([np.random.normal(0,1), np.random.normal(10,1), np.random.normal(0,0.01), 0, 0, 0, self.target_y, self.target_z, self.target_phi])
def step(self, action, state_specified=None):
if state_specified is None:
state_specified = self.state
else:
self.state = state_specified
A = np.array([[0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 0, 1], [0, 0, -self.g, 0, 0, 0], [0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]])
B = np.array([[0, 0], [0, 0], [0,0], [0,0], [-1/self.m, 0], [0, 1/self.Ixx]])
C = np.array([[1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0]])
K = action[0] * np.array([[-0.1171, -0.147, 1.5507, -0.2707, -0.1263, 0.2099],[-0.0031e-3, -0.0013e-3, 0.1065e-3, -0.0103e-3, -8.4749e-7, 0.0424e-3]])
#K = np.array([[action[0], action[1], action[2], action[3], action[4], action[5]],[action[6], action[7], action[8], action[9], action[10], action[11]]])
A_cl = A - B @ K
N = np.linalg.inv((C@np.linalg.inv(-A_cl))@B);
dx = A_cl@self.state[:6] + B@N@[self.target_y, self.target_z]
dist = np.sqrt((self.state[0]-self.target_y) ** 2 + (self.state[1]-self.target_z) ** 2)
# Perform Euler integration
self.state[0:6] += self.Ts * dx
self.episode_step -= 1
made_it = (self.target_y - self.eps <= self.state[0] <= self.target_y + self.eps) and (self.target_z - self.eps <= self.state[1] <= self.target_z + self.eps)
failed = (dist > self.flyOffThreshold) or (self.state[1] <= self.crashHeightThreshold) or ((self.state[3] or self.state[4]) > 10) or (abs(self.state[2]) > 1)
[reward, IsDone] = self.calc_reward(made_it, failed, action)
info = {}
return self.state, reward, IsDone, info
def reset(self):
y = np.random.normal(0,1)
z = np.random.normal(10,1)
phi = np.random.normal(0,0.01)
dz = 0
dy = 0
dphi = 0
self.state = np.array([y, z, phi, dy, dz, dphi, self.target_y, self.target_z, self.target_phi])
self.episode_step = 500
return self.state
def render(self):
pass
def calc_reward(self, madeit, failed, action):
d_ = np.sqrt((self.state[0] - self.state[6])**2 + (self.state[1] - self.state[7])**2)/self.flyOffThreshold
rew = 1 - d_**0.4
done = False
if madeit:
done = True
else:
rew += -0.25
if failed:
rew = -50
done = True
if env.episode_step <= 0:
done = True
return rew, done
env = Quad2DEnv()
episodes = 5
z_dynamics = []
y_dynamics = []
phi_dynamics = []
z_episode = []
y_episode = []
phi_episode = []
for episode in range(1, episodes + 1):
z_episode = []
y_episode = []
phi_episode = []
state = env.reset()
z_episode.append(state[1])
y_episode.append(state[0])
phi_episode.append(state[2])
done = False
total_reward = 0
while not done:
env.render()
action = env.action_space.sample()
nstate, reward, done, info = env.step(action)
z_episode.append(nstate[1])
y_episode.append(nstate[0])
phi_episode.append(state[2])
total_reward += reward
print("Episode: {}, Reward: {}, Steps: {} ".format(episode, total_reward,
500 - env.episode_step))
z_dynamics.append(z_episode)
y_dynamics.append(y_episode)
phi_dynamics.append(phi_episode)
z_dynamics = np.array([np.array(x) for x in z_dynamics])
y_dynamics = np.array([np.array(x) for x in y_dynamics])
phi_dynamics = np.array([np.array(x) for x in phi_dynamics])
fig = plt.figure(figsize=(10,5))
for iter in range(episodes):
ep = z_dynamics[iter]
t = np.arange(ep.shape[0])
ax = fig.add_subplot(1,5,iter+1)
plt.tight_layout()
ax.plot(t, ep)
plt.axhline(y=env.target_z, color='g', linestyle='--')
plt.show()
fig = plt.figure(figsize=(10,5))
for iter in range(episodes):
ep = y_dynamics[iter]
t = np.arange(ep.shape[0])
ax = fig.add_subplot(1,5,iter+1)
plt.tight_layout()
ax.plot(t, ep, 'r')
plt.axhline(y=env.target_y, color='g', linestyle='--')
plt.show()
fig = plt.figure(figsize=(10,5))
for iter in range(episodes):
ep = phi_dynamics[iter]
t = np.arange(ep.shape[0])
ax = fig.add_subplot(1,5,iter+1)
plt.tight_layout()
ax.plot(t, ep, 'c')
plt.axhline(y=env.target_phi, color='g', linestyle='--')
plt.show()
num_states = env.observation_space.shape[0]
print("Size of State Space -> {}".format(num_states))
num_actions = env.action_space.shape[0]
print("Size of Action Space -> {}".format(num_actions))
upper_bound = np.array([env.action_space.high[0], env.action_space.high[1], env.action_space.high[2], env.action_space.high[3], env.action_space.high[4],
env.action_space.high[5], env.action_space.high[6], env.action_space.high[7], env.action_space.high[8], env.action_space.high[9],
env.action_space.high[10], env.action_space.high[11]])
lower_bound = np.array([env.action_space.low[0], env.action_space.low[1], env.action_space.low[2], env.action_space.low[3], env.action_space.low[4],
env.action_space.low[5], env.action_space.low[6], env.action_space.low[7], env.action_space.low[8], env.action_space.low[9],
env.action_space.low[10], env.action_space.low[11]])
print("Action upper bounds: \n", upper_bound)
print("Action lower bounds: \n", lower_bound)
class Buffer:
def __init__(self, buffer_capacity=100000, batch_size=64):
# Number of "experiences" to store at max
self.buffer_capacity = buffer_capacity
# Num of tuples to train on.
self.batch_size = batch_size
# Its tells us num of times record() was called.
self.buffer_counter = 0
# Instead of list of tuples as the exp.replay concept go
# We use different np.arrays for each tuple element
self.state_buffer = np.zeros((self.buffer_capacity, num_states))
self.action_buffer = np.zeros((self.buffer_capacity, num_actions))
self.reward_buffer = np.zeros((self.buffer_capacity, 1))
self.next_state_buffer = np.zeros((self.buffer_capacity, num_states))
self.terminal_state_buffer = np.zeros((self.buffer_capacity, 1))
# Takes (s,a,r,s') obervation tuple as input
def record(self, obs_tuple):
# Set index to zero if buffer_capacity is exceeded,
# replacing old records
index = self.buffer_counter % self.buffer_capacity
#### TO DO : add terminal flag to obs_tuple input and update terminal state buffer #####
self.state_buffer[index] = obs_tuple[0]
self.action_buffer[index] = obs_tuple[1]
self.reward_buffer[index] = obs_tuple[2]
self.next_state_buffer[index] = obs_tuple[3]
self.buffer_counter += 1
# Eager execution is turned on by default in TensorFlow 2. Decorating with tf.function allows
# TensorFlow to build a static graph out of the logic and computations in our function.
# This provides a large speed up for blocks of code that contain many small TensorFlow operations such as this one.
@tf.function
def update(
self, state_batch, action_batch, reward_batch, next_state_batch,
):
# Training and updating Actor & Critic networks.
# See Pseudo Code.
with tf.GradientTape() as tape:
target_actions = target_actor(next_state_batch, training=True)
y = reward_batch + gamma * target_critic(
[next_state_batch, target_actions], training=True
)
critic_value = critic_model([state_batch, action_batch], training=True)
critic_loss = tf.math.reduce_mean(tf.math.square(y - critic_value))
critic_grad = tape.gradient(critic_loss, critic_model.trainable_variables)
critic_optimizer.apply_gradients(
zip(critic_grad, critic_model.trainable_variables)
)
with tf.GradientTape() as tape:
actions = actor_model(state_batch, training=True)
critic_value = critic_model([state_batch, actions], training=True)
# Used `-value` as we want to maximize the value given
# by the critic for our actions
actor_loss = -tf.math.reduce_mean(critic_value)
actor_grad = tape.gradient(actor_loss, actor_model.trainable_variables)
actor_optimizer.apply_gradients(
zip(actor_grad, actor_model.trainable_variables)
)
# We compute the loss and update parameters
def learn(self):
# Get sampling range
record_range = min(self.buffer_counter, self.buffer_capacity)
# Randomly sample indices
batch_indices = np.random.choice(record_range, self.batch_size)
# Convert to tensors
state_batch = tf.convert_to_tensor(self.state_buffer[batch_indices])
action_batch = tf.convert_to_tensor(self.action_buffer[batch_indices])
reward_batch = tf.convert_to_tensor(self.reward_buffer[batch_indices])
reward_batch = tf.cast(reward_batch, dtype=tf.float32)
next_state_batch = tf.convert_to_tensor(self.next_state_buffer[batch_indices])
terminal_state_batch = tf.convert_to_tensor(self.terminal_state_buffer[batch_indices])
#### TO DO : add sampled terminal state to the update function below #####
self.update(state_batch, action_batch, reward_batch, next_state_batch)
# This update target parameters slowly
# Based on rate `tau`, which is much less than one.
@tf.function
def update_target(target_weights, weights, tau):
for (a, b) in zip(target_weights, weights):
a.assign(b * tau + a * (1 - tau))
def get_actor():
# Initialize weights between -3e-3 and 3-e3
last_init = tf.random_uniform_initializer(minval=-0.003, maxval=0.003)
inputs = Input(shape=(num_states,))
out = Dense(128, activation="relu")(inputs)
out = Dense(128, activation="relu")(out)
out = Dense(256, activation="relu")(out)
out = Dense(256, activation="relu")(out)
out = Dense(512, activation="relu")(out)
out = Dense(512, activation="relu")(out)
out = Dense(512, activation="relu")(out)
outputs = Dense(num_actions, activation="tanh", kernel_initializer=last_init)(out)
model = tf.keras.Model(inputs, outputs)
return model
def get_critic():
# State as input
state_input = Input(shape=(num_states))
state_out = Dense(128, activation="relu")(state_input)
state_out = Dense(256, activation="relu")(state_out)
state_out = Dense(512, activation="relu")(state_out)
state_out = Dense(512, activation="relu")(state_out)
state_out = Dense(512, activation="relu")(state_out)
# Action as input
action_input = Input(shape=(num_actions))
action_out = Dense(128, activation="relu")(action_input)
action_out = Dense(256, activation="relu")(action_input)
action_out = Dense(256, activation="relu")(action_input)
action_out = Dense(512, activation="relu")(action_input)
action_out = Dense(512, activation="relu")(action_input)
action_out = Dense(512, activation="relu")(action_input)
# Both are passed through seperate layer before concatenating
concat = Concatenate()([state_out, action_out])
out = Dense(256, activation="relu")(concat)
out = Dense(256, activation="relu")(out)
out = Dense(256, activation="relu")(out)
out = Dense(256, activation="relu")(out)
out = Dense(64, activation="relu")(out)
outputs = Dense(1)(out)
# Outputs single value for give state-action
model = tf.keras.Model([state_input, action_input], outputs)
return model
def policy(state, evaluation = False):
sampled_actions = tf.squeeze(actor_model(state))
# Adding noise to action
if evaluation is False:
sampled_actions = sampled_actions.numpy() + np.random.randn(*(sampled_actions.numpy().shape))
else:
sampled_actions = sampled_actions.numpy()
sampled_actions *= upper_bound
# We make sure action is within bounds
legal_action = np.clip(sampled_actions, lower_bound, upper_bound)
return [np.squeeze(sampled_actions)]
actor_model = get_actor()
critic_model = get_critic()
target_actor = get_actor()
target_critic = get_critic()
# Making the weights equal initially
target_actor.set_weights(actor_model.get_weights())
target_critic.set_weights(critic_model.get_weights())
# Learning rate for actor-critic models
critic_lr = 0.002
actor_lr = 0.001
critic_optimizer = tf.keras.optimizers.Adam(critic_lr)
actor_optimizer = tf.keras.optimizers.Adam(actor_lr)
total_episodes = 100
# Discount factor for future rewards
gamma = 0.99
# Used to update target networks
tau = 0.005
buffer = Buffer(50000, 64)
# TRAIN
# To store reward history of each episode
ep_reward_list = []
# To store average reward history of last few episodes
avg_reward_list = []
# Takes about 4 min to train
for ep in range(total_episodes):
prev_state = env.reset()
episodic_reward = 0
while True:
# Uncomment this to see the Actor in action
# But not in a python notebook.
# env.render()
tf_prev_state = tf.expand_dims(tf.convert_to_tensor(prev_state), 0)
action = np.array(policy(tf_prev_state, evaluation=False))
action = np.squeeze(action)
# Recieve state and reward from environment.
state, reward, done, info = env.step(action)
buffer.record((prev_state, action, reward, state))
episodic_reward += reward
buffer.learn()
update_target(target_actor.variables, actor_model.variables, tau)
update_target(target_critic.variables, critic_model.variables, tau)
# End this episode when `done` is True
if done:
break
prev_state = state
ep_reward_list.append(episodic_reward)
# Mean of last 10 episodes
avg_reward = np.mean(ep_reward_list[-10:])
print("Episode * {} * Avg Reward is ==> {}".format(ep, avg_reward))
avg_reward_list.append(avg_reward)
# Plotting graph
# Episodes versus Avg. Rewards
plt.plot(avg_reward_list)
plt.xlabel("Episode")
plt.ylabel("Avg. Epsiodic Reward")
plt.show()
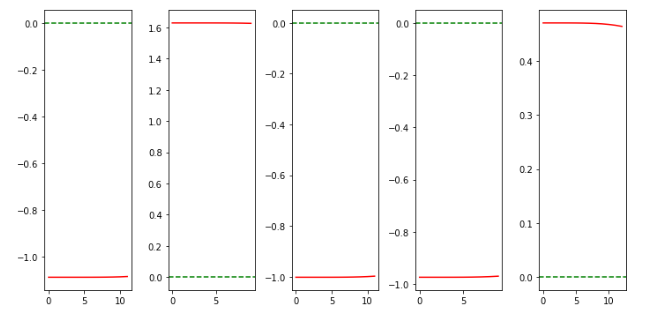
episodes = 5
z_dynamics = []
y_dynamics = []
phi_dynamics = []
z_episode = []
y_episode = []
phi_episode = []
for episode in range(1, episodes + 1):
z_episode = []
y_episode = []
phi_episode = []
state = env.reset()
state = np.array([-1+np.random.rand(),9+np.random.rand(),0.1,1,0,0,env.target_z,env.target_y, env.target_phi])
z_episode.append(state[1])
y_episode.append(state[0])
phi_episode.append(state[2])
done = False
total_reward = 0
while not done:
state = np.reshape(state, (1,9))
env.render()
action = np.squeeze(np.array(policy(state,evaluation=True)))
state = np.squeeze(state)
state, reward, done, info = env.step(action, state)
z_episode.append(state[1])
y_episode.append(state[0])
phi_episode.append(state[2])
total_reward += reward
print("Episode: {}, Reward: {}, Steps: {} ".format(episode, total_reward,
500 - env.episode_step))
z_dynamics.append(z_episode)
y_dynamics.append(y_episode)
phi_dynamics.append(phi_episode)
z_dynamics = np.array([np.array(x) for x in z_dynamics])
y_dynamics = np.array([np.array(x) for x in y_dynamics])
phi_dynamics = np.array([np.array(x) for x in phi_dynamics])
fig = plt.figure(figsize=(10,5))
for iter in range(episodes):
ep = z_dynamics[iter]
t = np.arange(ep.shape[0])
ax = fig.add_subplot(1,5,iter+1)
plt.tight_layout()
ax.plot(t, ep)
plt.axhline(y=env.target_z, color='g', linestyle='--')
plt.show()
fig = plt.figure(figsize=(10,5))
for iter in range(episodes):
ep = y_dynamics[iter]
t = np.arange(ep.shape[0])
ax = fig.add_subplot(1,5,iter+1)
plt.tight_layout()
ax.plot(t, ep, 'r')
plt.axhline(y=env.target_y, color='g', linestyle='--')
plt.show()
fig = plt.figure(figsize=(10,5))
for iter in range(episodes):
ep = phi_dynamics[iter]
t = np.arange(ep.shape[0])
ax = fig.add_subplot(1,5,iter+1)
plt.tight_layout()
ax.plot(t, ep, 'c')
plt.axhline(y=env.target_phi, color='g', linestyle='--')
plt.show()