Table of Contents
Project Overview
This project was entered in the AI Tracks at Sea Challenge hosted by the US Navy. I led our team at the FAMU-FSU College of Engineering comprised of four members including myself. We placed 2nd out of 31 teams that participated and won $45,000. The following link takes you to the official challenge page with winners listed: https://www.challenge.gov/challenge/AI-tracks-at-sea/
A computer vision system is developed that will plot the tracks of shipping traffic exclusively using the passive sensing capability of onboard cameras. Each team is initially provided with a dataset consisting of recorded camera imagery of vessel traffic along with the recorded GPS track of a vessel of interest that is seen in the imagery.
The objective of the competition is to create a computer vision system that can output GPS trajectories of a target ship given a video of the ship recorded on a monocular camera.
Solution Approach
The proposed software architecture was made up of 4 major sub-components. The entire pipeline was fully implemented in Python using OpenCV, Tensorflow, UTM, and scikit-learn and run on an Nvidia Jetson TX2 for about 2 minutes 15 seconds. The detection subsystem ran at an average 15 FPS on a GPU with the inference executing at more than 100 hz on a CPU while the interpolation runs at about 10 hz on CPU. I was directly responsible for the first step of the framework – detection and localization of the ship in the video feed.
The four sub-components are:
- Detection
- Inference
- Interpolation
- Error Evaluation
Object Detection and Localization
Approximately 20 mins of the training videos were decomposed into individual image frames. In each image, a bounding box was hand labelled over the target ship. This provided the convolutional neural network with the target class that was asked to be detected and localized. For this project, the YOLOv4 object detection framework was used.
To improve the model’s ability to generalize to unseen footage, the training data was supplemented with data augmented samples. These augmentations included added rotation, brightness, exposure, blue and noise applied to the original training samples. This improved the robustness of the object detection model.
The software was coded in Python and the YOLOv4 detector ran inference on each frame of the provided videos in the test set. The object detection portion of the code provided a trajectory of the target ship in image frame which was used in the subsequent steps to learn the mapping between image frame and world GPS location.
Image Detections to GPS Mapping
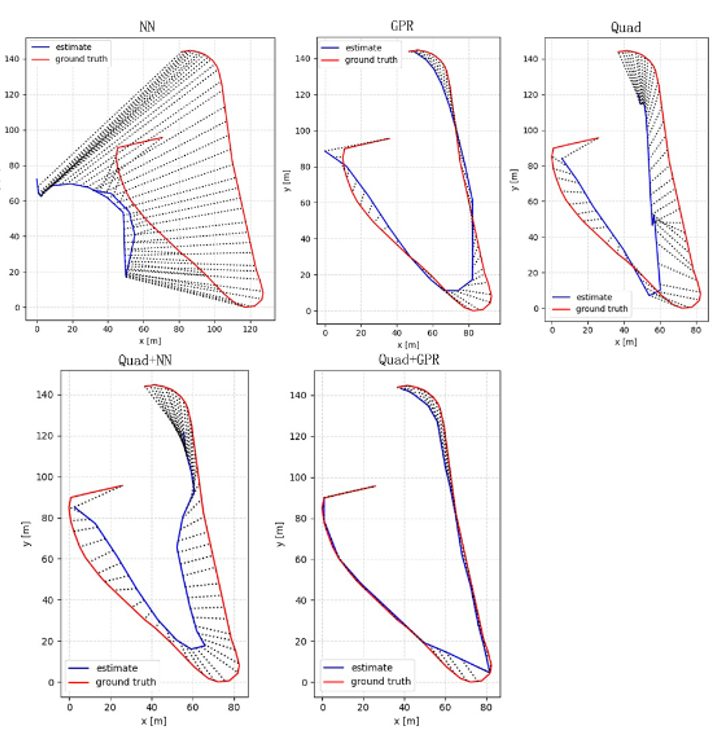
In this work, it is assumed that a single monocular camera is used – whose calibration information is unknown. To regress the mapping between image frame and world GPS coordinates, a kernel regression method is used. The below graphs show multiple approaches that were tested and the corresponding GPS trajectories predicted by the model vs the ground truth data (NN: neural network, GPR: Gaussian model regression, Quad: kernel regression with quadratic kernel). From the graphs, it is evident that the best approach was obtained using a quadratic approximation with Gaussian model regression.